Dokumentsets sind ein sehr schicke Funktion von SharePoint Server. Leider gibt es die nur in der Server-Version – also nicht wenn man nur Foundation einsetzt.
Was also tun, wenn der Kunde nur eine Foundation hat, aber Anforderungen hat, die nach den Eigenschaften eines Document-Sets schreien?
Die Anforderungen
Vielleicht zunächst zu den Anforderungen des Kunden. Die Anforderung war, dass es ein Dokument gibt, zu welchem Anlagen existieren. Also eine Klassischer Master-Detail Beziehung zwischen den Dokumenten.
SharePoint kennt ja durchaus Anlagen – aber nur für Listenelemente, nicht bei Dokumenten. und Anlagen habe den Nachteil, dass es keine Versionierung und eigene Meta-Daten gibt. Das ist irgendwie doof. Schöner wäre es, wenn man also zu einem Dokument beliebig viele Anlagen anfügen könnte.
Natürlich hat mir diese Frage keine Ruhe gelassen und ich habe mir gedacht, dass sich das doch recht einfach lösen lassen muss.
Ein Lösungspfad
Fangen wir einmal ganz einfach an. Zuerst einmal brauchen wir zwei Dokument-Bibliotheken, eine für die Dokumente und eine für die Anlagen. In der Bibliothek der Anlagen wird dann eine Nachschlage-Spalte hinzugefügt, die auf die Dokumente verweist. Somit kann man also Anlagen hochladen und die mit einem Dokument verknüpfen.

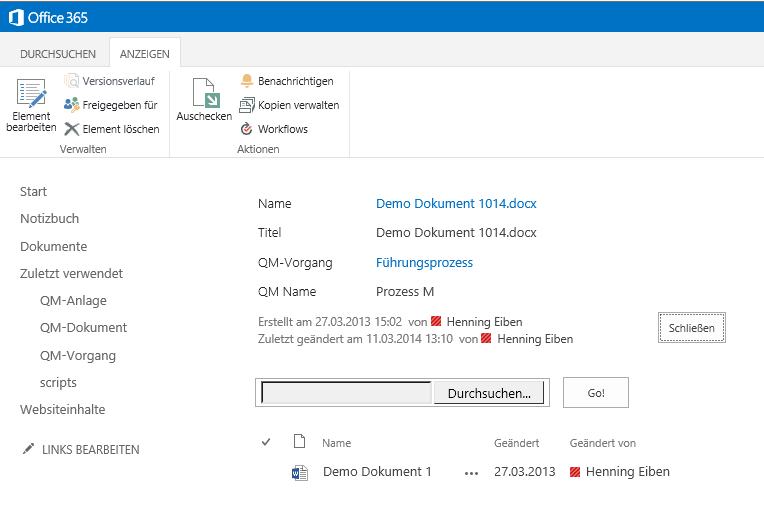
Als nächstes sollten die Anlage immer beim jeweiligen Dokument mit angezeigt werden. Dazu wir die Standard-Ansicht des Dokuments bearbeitet und ein App-WebPart für die Anlagen Hinzugefügt.

Nun muss an das WebPart noch ein Filter übergeben werden. Dazu wird die ID des aktuellen Dokuments übergeben und in der Liste der Anlage in der Spalte QM-Dokumente gefiltert.

Wenn man nun also ein Dokument öffnet, sieht man nur die Anlage, die mit diesem Dokument verbunden sind.
Allerdings hat diese Lösung noch einen Haken: sie ist unhandlich in der Pflege. Wenn man eine neue Anlage zu eine Dokument hinzufügen will, dann muss man die Anlage in die Liste der Anlagen hochladen und in den Meta-Daten auf das Dokument verweisen. Das ist irgendwie doof. Besser wäre es ja, wenn man z.B. in der Detail-Ansicht des Dokuments sagen könnte “bitte eine neue Anlage für dieses Dokument hochladen”.
Das Customizing
Mit ein wenig JavaScript kann man das Handling der Lösung vereinfachen. Zunächst wird jQuery, ein File-Input Element und ein Button gebraucht.
<script type="text/javascript" src="https://mytenant.sharepoint.com/qm/scripts/jquery-1.8.2.min.js"></script>
<input type="file" id="fileSelectorInput">
<input type="button" onClick="javascript: DoUpload();" value="Go!">
Nun folgt also die Magie. Die liegt hier natürlich in der Funktion DoUpload. Hier wird zunächst die Datei aus dem Dateisystem gelesen und dann als ByteCharacter-Array an eine weiter Funktion übergeben.
function DoUpload() {
var fileInput = jQuery('#fileSelectorInput');
var file = fileInput[0].files[0];
var reader = new FileReader();
reader.onload = function (result) {
var fileName = '',
libraryName = '',
fileData = '';
var byteArray = new Uint8Array(result.target.result)
for (var i = 0; i < byteArray.byteLength; i++) {
fileData += String.fromCharCode(byteArray[i])
}
DoUploadInternal(file.name, fileData);
};
reader.readAsArrayBuffer(file);
}
Soweit ist ja noch alles ganz Simple. Als nächstes wird die Datei mittels JSOM in den SharePoint geladen, um direkt auch die Meta-Daten setzen zu können.
Zunächst wird die ID des aktuellen Dokuments aus der URL gelesen und der Wert des Feldes QMName aus dem Anzeigeformular. Denn wir wollen der Anlage nicht nur einen Verweis auf das aktuelle Dokument geben, sondern auch die Meta-Daten aus dem Feld QMName mit an die Anlage übergeben.
JSRequest.EnsureSetup();
var qmName = jQuery('h3:contains("QM Name")').closest('td').next('td').text();
var qmDokumentId = JSRequest.QueryString["ID"];
Nun brauchen wir einen ClientContext, damit wir eine neue Datei für SharePoint anlegen können. Dort fügen wir dann das Character-Array unserer Datei als Content an.
clientContext = new SP.ClientContext.get_current();
var oWebsite = clientContext.get_web();
var oList = oWebsite.get_lists().getByTitle("QM-Anlage");
var fileCreateInfo = new SP.FileCreationInformation();
fileCreateInfo.set_url(fileName);
fileCreateInfo.set_content(new SP.Base64EncodedByteArray());
for (var i = 0; i < fileContent.length; i++) {
fileCreateInfo.get_content().append(fileContent.charCodeAt(i));
}
newFile = oList.get_rootFolder().get_files().add(fileCreateInfo);
clientContext.load(newFile);
Nun müssen wir noch die Meta-Daten setzen. Dazu holen wir zunächst alle Feld-Informationen und setzen dann den Wert für QMName und erstellen einen Lookup auf das aktuelle Dokument.
item = newFile.get_listItemAllFields();
clientContext.load(item);
item.set_item("QMName", qmName);
var object = new SP.FieldLookupValue();
object.set_lookupId(qmDokumentId);
item.set_item("QMDokument", object);
item.update();
clientContext.executeQueryAsync(successHandler, errorHandler);
Am Schluss wird das Ganze dann als asynchrone Query an den Server gesendet. Im successHandler wird dann noch die aktuelle Seite aktualisiert, damit das neu hinzufügte Dokument auch in der Liste erscheint.
SP.UI.ModalDialog.RefreshPage(SP.UI.DialogResult.OK);
Fazit
Mit ein bisschen Creativität und ein wenig JavaScript Anpassungen kann man schon ganz ordentlich etwas aus SharePoint heraus kitzeln.